Words Are Not Numbers - The Barrier that Stops Deep Learning from Understanding Written Language.

On the back of developments in deep learning and general progress in Artificial Intelligence, there has been impressive progress in Natural Language Processing (NLP) over the past few years. Starting with the popularity of word embedding techniques such as Word2Vec and GloVe, to recent developments in transfer learning using pre-trained models like Allen AI’s ELMo, Google AI’s BERT and Open AI’s GPT-2, not a week goes by without a new set of state of the art numbers being reported.
Fundamental to these NLP approaches based on deep learning is the step of turning words into a form that can be understood by the neural networks that are being trained to complete the task at hand. This means transforming words into a vector space, a set of numbers. Unfortunately, these statistical language representations are unable to simultaneously capture both the precision and flexibility with which language is used. Rather than enabling progress towards understanding language, it seems words are imprisoned by these vector spaces and are not able to break free from the constraints of their training set (however big it is!).
Counting words
Early attempts at NLP focused on hand-crafting or inferring syntactic rules that allowed language to be parsed. These approaches proved to be brittle, incomplete and didn’t provide a clear path towards general language understanding. With the growing importance of information retrieval, and search in particular, and starting with simple techniques such as bag of words and tf-idf, statistical approaches came into play. NLP systems have followed suit, counting words in ever more sophisticated ways.
Although not an NLP system as such, it is illustrative to look at Google’s search as a baseline for statistical approaches to language. Using click-through rate as a proxy for match quality, usage stats¹ show that 31% of users click on the first result, and 75% of all clicks are in the top 3 results. Google seems to be doing a great job of selecting the right result for specific queries. But, you will know from your own searches that, as soon as you look beyond the first page of results that the matches become much weaker (less than 1% of results are ever clicked after the first page). A recent study² also showed that almost half of all searches now result in no clickthroughs. This may be because the answer that the searcher was looking for is available in the snippets or structured search results that Google displays, but it also contains cases where the searcher keeps needing to reformulate their search question to find an acceptable answer, or a suitable answer just wasn’t matched. Matches beyond the structured results that Google provides (e.g. Wikipedia, places, the answer box, “people also ask”) look increasingly poor.
That’s all very well for search, but how does this translate into an NLP system? Google is only dealing with one simple question, matching to the best result, and mostly finds the right answer. Unfortunately, ‘mostly’ is not good enough when you are reading whole articles or trying to carry out a conversation. Any single error can be amplified by any text or interpretation that follows. Even with very high rates of accuracy (way beyond the current state of the art), ‘nearly right’ can quickly turn into ‘rarely right’ as a conversation proceeds or text is (mis)understood.

FROM: OH, THE PLACES YOU’LL GO! (DR. SEUSS)
With its ever-increasing accuracy, one language task that many people think is solved is machine translation³. It was one of the first areas where NLP from the lab was let loose on the public at scale. However, taking a simple extract from Dr. Seuss quickly highlights the challenges that remain. Dr. Seuss is great (of course!) because he uses nice simple words and sentence structures. We experimented with Google Translate⁴, which started to use Neural Machine Translation (NMT) in 2016, and translated from English through the top 10: spoken languages, native languages of internet users and online content languages⁵, and back into English to see how close they were to the original text.

While we might not expect to get the poetry of the original, all the translations seem to make some basic missteps along the way. All versions seem to have problems telling the difference between feet, shoes and legs, and have different opinions on whether you, I or they are on their own! Comparing the different language types, the translation through the top 10 languages by online content does the best (49% match based on straight word count). It even retains a bit of the rhyming in the last sentences. This is to be expected because these languages will have the most online content from which the NMT can be trained. The user language (34%) and spoken language (32%) translations do much worse, and make clear nonsensical errors that the content-based results largely avoid — “one foot on one foot” “legs in your legs” — although Dr. Seuss might be proud of!
This example used a very short text with simple words and sentence structure. Imagine if full texts are to be read and translated using a full range of language, where a translation choice might depend on some statement earlier in the text. At a glance, translations look ‘good enough’ but digging deeper they leave a lot to be desired.
Understanding words
As we have said, fundamental to the popular deep learning approaches to NLP is the translation of words into a vector space. These vector spaces are representations of the meaning of a word by putting it into the context of other similar words. One of the most famous examples of this in action — which seems to demonstrate semantic knowledge — comes from embeddings trained using Word2Vec⁶:
vector(”King”) — vector(”Man”) + vector(”Woman”) -> vector(“Queen”)
There are differences between how word embeddings are generated based on the approach but fundamentally they are trained by trying to predict a word from the context of surrounding words in an existing body of text.
Jane was phishing for [ — — — ] account passwords // George was fishing from the river [ — — — ]
A likely word for both these sentences is “bank”. However, this example illustrates a problem that existed with early approaches to word embeddings. A word could only have a single representation. In these cases, we want to distinguish between a bank that looks after money vs. a bank at the side of a river. This was addressed with the introduction of contextual word embeddings, such as ELMo⁷, where both the word and the context are held in the vector representation. This change, with better inputs, led to a step-change shift in state of the art across a broad range of NLP benchmarks.
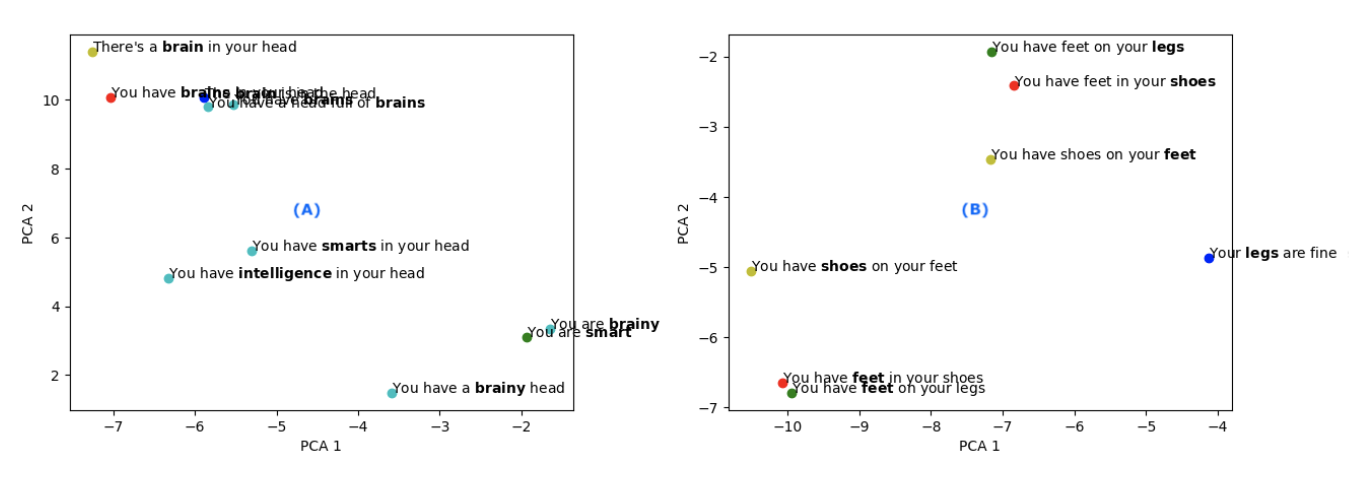
If contextual word embeddings have improved state of the art then why are we still having trouble with simple translations? We can get a clue to this by examining the ELMo contextual word embeddings for some of these translations. These pre-trained models have been built from similar content (i.e. open web sources) that have been used by Google to build their NMT models, so they may exhibit similar biases.
(A) The embeddings for the translations of “You have brains in your head” show that all the embeddings equate “brain” and “brains” to the lump of material in your head (top left area). There is no recognition of the other meaning of brains to mean intelligence, although if you try “brainy” then this moves close to smart or intelligence (bottom right area).
(B) For translations of “You have feet in your shoes” you can see that in the context of “in/on your” that feet, shoes and legs are very closely aligned (top right area). But “feet”, “shoes” and “legs” are seen as quite different attributes when viewed in other contexts.
Both of these embeddings reinforce the interpretation that the various translations have made on the original text. So while contextual word embeddings have enabled across the board improvements in NLP tasks, they are still extremely limited in representing the meaning of words and constrained by the data that was used to train them.
So, building very large models based on parsing large chunks of content (e.g. the large ELMo model has 93.6M parameters and was built on 5.5B tokens sourced from the web) doesn’t seem to have captured sufficient detail to accurately understand the meaning of words. Where can the definitions of words be captured that will allow accurate interpretation and generalisation? The same place a human would go, the dictionary.

Clearly the dictionary contains the answers to the multiple meanings of brains and the difference between legs, feet and shoes. Building a model that represents this knowledge can offer a similar capability to word embeddings, understanding the relationships between words and the context in which they are used, but without losing accuracy and not limited by the training set. This approach does not fit with current deep learning-based strategies as the model is necessarily symbolic rather than statistical. Although symbolic, these models are distinct from early symbolic attempts at NLP which were focused around the syntax. These language models are focused on semantics; capturing the meaning of words, their roles within the text, and combining them to begin to understand language.
Discussion
There may be more gains to be made and new benchmarks to be created as ever more complex neural language models are created and more training data is read; but just because there is a lot of data available, it doesn’t mean we should train on it, and just because the compute resource is there doesn’t mean we should consume it. There already seem to be decreasing returns as models and training data are scaled up massively but only lead to relatively small improvements in precision⁸. We expect that this will continue as accuracy starts to become an intractable problem and small errors lead to bigger ones as more text needs to be understood or as a conversation proceeds⁹. With statistical models, generalisation to content beyond the training set will always lose precision.
The answer to this loss of precision is bootstrapping language understanding by building precise representations of small languages and using these to understand larger texts. Much as you learnt words as a child as you interacted with the world; discovering the meaning of a word and slowly starting to understand how to combine words to be understood yourself. At glass.ai, we have been building small domain-specific language models to perform a wide variety of social, economic and business research from open web content. These required the application of the models across core NLP tasks, such as text classification, word disambiguation, entity recognition, information extraction, semantic role labelling, entity linking, and sentiment analysis, and have been used to explore, categorise, summarise, and map huge chunks of the open web. This large scale consumption of text has demonstrated that the precision of these models means they can generalise to and ultimately understand very large bodies of unseen content.
*******************
[1]: Brian Dean. Here’s What We Learned About
Organic Click Through Rate. https://backlinko.com/google-ctr-stats. 2019.
[2]: George Nguyen. 49% of all Google searches are no-click, study finds. https://searchengineland.com/49-of-all-google-searches-are-no-click-study-finds-318426. 2019.
[3]: Cade Metz. An Infusion of AI Makes Google Translate More Powerful Than Ever. https://www.wired.com/2016/09/google-claims-ai-breakthrough-machine-translation/. 2016.
[4]: Yonghui Wu et. al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. https://ai.google/research/pubs/pub45610. 2016.
[5]: Thomas Devlin. What Are The Most-Used Languages On The Internet? https://www.babbel.com/en/magazine/internet-language/. 2019.
[6]: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. https://arxiv.org/abs/1301.3781. 2013.
[7]: Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer. Deep contextualized word representations. https://arxiv.org/abs/1802.05365. 2018.
[8]: Alec Radford et. al. Better Language Models
and Their Implications. https://openai.com/blog/better-language-models/. 2019.
[9]: Christopher D. Manning. Part-of-speech tagging from 97% to 100%: is it time for some linguistics? https://dl.acm.org/citation.cfm?id=1964816. 2011.